所谓优雅终止,就是保证在销毁 Pod 的时候保证对业务无损,比如在业务发版时,让工作负载能够平滑滚动更新。 Pod 在销毁时,会停止容器内的进程,通常在停止的过程中我们需要执行一些善后逻辑,比如等待存量请求处理完以避免连接中断,或通知相关依赖进行清理等,从而实现优雅终止目的。
pod终止流程
我们先了解下容器在 Kubernetes 环境中的终止流程:
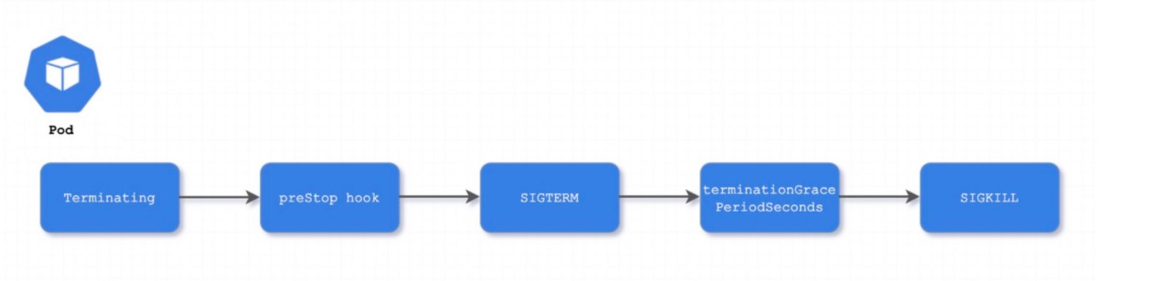
Pod 被删除,状态变为
Terminating。从 API 层面看就是 Pod metadata 中的 deletionTimestamp 字段会被标记上删除时间。kube-proxy watch 到了就开始更新转发规则,将 Pod 从 service 的 endpoint 列表中摘除掉,新的流量不再转发到该 Pod。
kubelet watch 到了就开始销毁 Pod。
3.1. 如果 Pod 中有 container 配置了 preStop Hook ,将会执行。
3.2. 发送
SIGTERM信号给容器内主进程以通知容器进程开始优雅停止。3.3. 等待 container 中的主进程完全停止,如果在
terminationGracePeriodSeconds内 (默认 30s) 还未完全停止,就发送SIGKILL信号将其强制杀死。3.4. 所有容器进程终止,清理 Pod 资源。
3.5. 通知 APIServer Pod 销毁完成,完成 Pod 删除。
合理使用preStop
在某些极端情况下,Pod 被删除的一小段时间内,仍然可能有新连接被转发过来,因为 kubelet 与 kube-proxy 同时 watch 到 pod 被删除,kubelet 有可能在 kube-proxy 同步完规则前就已经停止容器了,这时可能导致一些新的连接被转发到正在删除的 Pod,而通常情况下,当应用收到 SIGTERM 后都不再接受新连接,只保持存量连接继续处理,所以就可能导致 Pod 删除的瞬间部分请求失败。
这种情况下,我们也可以利用 preStop 先 sleep 一小下,等待 kube-proxy 完成规则同步再开始停止容器内进程:
1 | lifecycle: |
配置保守的更新策略
如果对稳定性要求较高,可以设置比较保守的滚动更新策略:
保持足够多的可用副本数量。避免在滚动时可以正常处理请求的 Pod 数量减少导致部分请求因后端 Pod 处理不过来而异常。
减缓发版速度。一方面可以避免新版应用引入难以发现的问题快速扩散,方便发现后及时回滚恢复;另一方面,如果使用 LB 直通 Pod,更新过程中,云厂商的
service-controller或cloud-controller-manager组件会更新 LB 的后端 rs,这个过程是异步的,在某些极端场景下,可能出现 LB 后端的 rs 还没更新,旧的 Pod 副本已经被销毁了,从而导致流量转发到已销毁的 Pod 而引发异常。给新副本留预热时间。新副本启动时,多给应用一些时间进行准备,避免某些应用虽然探测接口返回就绪,但实际处理能力还没跟上,过早转发请求过来可能导致异常。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34apiVersion: apps/v1
kind: Deployment
metadata:
name: nginx
spec:
replicas: 1
selector:
matchLabels:
app: nginx
strategy:
type: RollingUpdate
rollingUpdate: # 单个串行升级,等新副本 ready 后才开始销毁旧副本
maxUnavailable: 0 # 更新过程中,允许不可用的旧 Pod 数量
maxSurge: 1 # 更新过程中,允许超出期望副本数的新 Pod 数量
template:
metadata:
labels:
app: nginx
spec:
containers:
- name: nginx
image: nginx:latest
startupProbe:
httpGet:
path: /
port: 80
successThreshold: 5 # 新副本启动时,连续探测成功多次后才交给 readinessProbe 探测
periodSeconds: 5
readinessProbe:
httpGet:
path: /
port: 80
successThreshold: 1 # 运行过程中探测 1 次成功就认为 ready,可在抖动导致异常后快速恢复服务
periodSeconds: 5长连接场景
如果业务是长链接场景,比如游戏、会议、直播等,客户端与服务端会保持着长链接,销毁 Pod 时需要的优雅终止的时间通常比较长 (preStop + 业务进程停止超过 30s),有的极端情况甚至可能长达数小时,这时候可以根据实际情况自定义 terminationGracePeriodSeconds,避免过早的被 SIGKILL 杀死,示例:
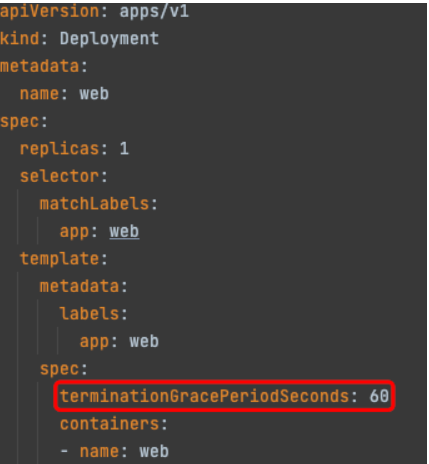
具体设置多大可以根据业务场景最坏的情况来预估,比如对战类游戏场景,同一房间玩家的客户端都连接的同一个服务端 Pod,一轮游戏最长半个小时,那么我们就设置 terminationGracePeriodSeconds 为 1800。
如果不好预估最坏的情况,最好在业务层面优化下,比如 Pod 销毁时的优雅终止逻辑里面主动通知下客户端,让客户端连到新的后端,然后客户端来保证这两个连接的平滑切换。等旧 Pod 上所有客户端连接都连切换到了新 Pod 上,才最终退出。

